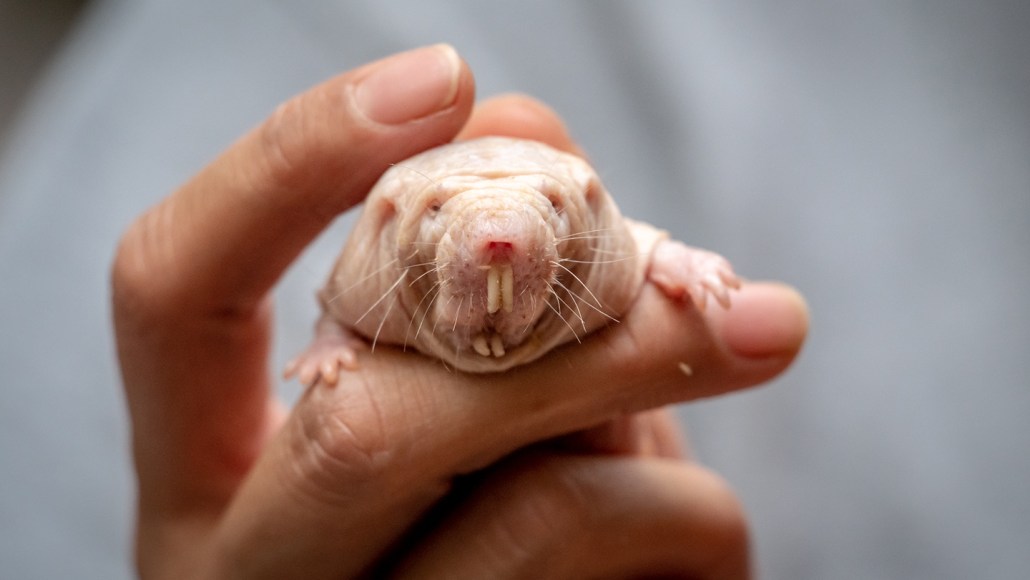
Naked mole-rats live in highly cooperative societies, but they can be vicious fighters. Scientists recently discovered how naked mole-rat queens keep the peace.
John Brighenti/Flickr (CC BY 2.0)
Naked mole-rats live in highly cooperative societies, but they can be vicious fighters. Scientists recently discovered how naked mole-rat queens keep the peace.
John Brighenti/Flickr (CC BY 2.0)







