Making Data Work
Researchers pursue analogy between statistical evidence and thermodynamics
A fundamental problem for almost all science is how to tell a fluke from a fact.
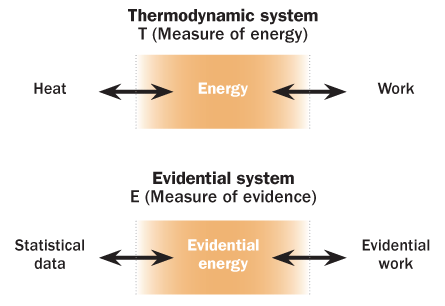
Researchers pursue analogy between statistical evidence and thermodynamics
A fundamental problem for almost all science is how to tell a fluke from a fact.