Anshumali Shrivastava uses AI to wrangle torrents of data
Big data is growing faster than current computer programs can keep up

GET SMART Computer scientist Anshumali Shrivastava is devising clever ways to help computer programs work smarter, not harder.
A. Shrivastava
Anshumali Shrivastava, 33
Computer Science
Rice University
 The world is awash in data, and Anshumali Shrivastava may save us from drowning in it.
The world is awash in data, and Anshumali Shrivastava may save us from drowning in it.
Every day, over 1 billion photos are posted online. In a single second, the Large Hadron Collider can churn out a million gigabytes of observations. Big data is ballooning faster than current computer programs can analyze it.
“We have this huge ocean of data,” says electrical and computer engineer Richard Baraniuk of Rice University in Houston, “and we’ve got to suck it out through a garden hose.”
So computer scientist Anshumali Shrivastava, 33, is designing a new generation of artificial intelligence programs to efficiently process floods of information.
“He’s very creative” in his strategies to wrangle unwieldy datasets, says Piotr Indyk, an electrical engineer and computer scientist at MIT. “Some of these things I say, ‘I wish I came up with that.’ They’re clear, beautiful and they work.”
Shrivastava got into artificial intelligence because number-crunching algorithms that solve real-world problems are “where you see math in action,” he says. But as a Ph.D. student in computer science at Cornell University, Shrivastava realized how inefficient artificial neural networks, today’s premiere AI programs, really are.
Neural networks are made of pieces of code called artificial neurons. To learn a task such as image recognition, an AI network might study labeled images, with each of the artificial neurons in the network gaining expertise at recognizing certain patterns.
But even as they specialize, all the neurons in a typical network keep studying all incoming information. When the network sees a cat photo, for example, even neurons responsible for noticing trucks pay attention. That’s unnecessarily time- and energy-consuming, Shrivastava says.
In graduate school, Shrivastava found a way to identify and activate only the neurons most relevant to each input. He used hash functions, computational tools that organize records in databases much like the Dewey Decimal System organizes books in a library.
Orderly storage
A computer can organize records in a database by feeding each document into a hash function, which assigns the record a hash code. Similar documents are assigned similar hash codes and stored in the same “bucket” in a hash table — similar to the way books of the same subject are shelved together in a library.
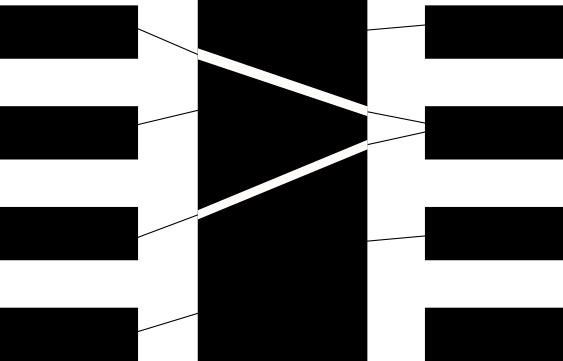
Shrivastava fashioned a set of hash functions to organize and quickly locate virtual neurons in a network based on their relevancy to a given input — so you could find all the cat neurons and ignore truck neurons.
“I was thinking about this problem for more than two years,” he says. “You keep all your hard problems in the back of your head.” He’d return to this one when he had some time and usually get nowhere. But the day the path to an answer came to him, he solved it in a couple of hours. He recalls sitting in his bedroom, reading and rereading his solution to convince himself it would actually work.
The system he came up with may be considered “the best research work in machine learning in that year,” says Moshe Vardi, also a computer scientist at Rice. It won the Outstanding Paper Award at the 2014 Conference on Neural Information Processing Systems.
Since then, Shrivastava has built an image-classifying neural network that works about as well as standard networks, but uses 95 percent fewer computations. Such efficiency could free up time and energy for an AI program to process other information, for instance, audio for speech recognition, paving the way for more versatile artificial intelligence.
He has also developed other ways to streamline computation since joining the Rice faculty in 2015. He’s “incredibly bright and incredibly fast,” Vardi says. “We sometimes have to run after him, because his mind is racing ahead.”
Shrivastava and colleagues at Rice and Duke University recently applied hashing to databases of Syrian civil war victims. Getting an accurate death count for the Syrian conflict, to help prosecute perpetrators of crimes against humanity has proved difficult. Databases of victims reported by family members, the media and other sources contain duplicate records; it would take a computer more than a week to compare all 354,000 records to each other to find repeats.
Once Shrivastava’s computer program assigned each record in four victim databases a hash code, it used those codes to identify likely duplicates in just a couple of minutes. The program, reported in June in the Annals of Applied Statistics, then checked only those records for matches.
Closer to home, Shrivastava and colleagues created a smartphone app for navigating shopping malls or other large buildings based on photos of a person’s surroundings. The app distilled user-taken photos into hash codes to compare with reference photo codes, pinpointing locations within two seconds.
With the flood of Big Data growing, it would be easy for Shrivastava to get overwhelmed and discouraged. Fortunately, “there’s not a glum bone in his body,” Baraniuk says.
Shrivastava might stall on a particular problem for months or years before getting the kind of brain blast that led to his hash-based eureka moment. But when he can kick a slow-moving computer system into high gear, he says, “that’s worth it.”