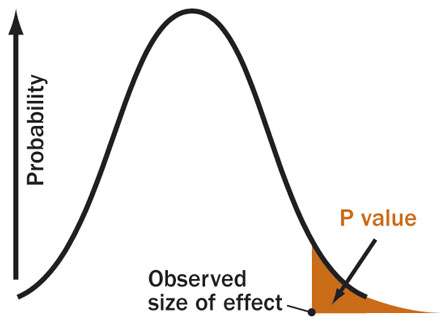
For better or for worse, science has long been married to mathematics. Generally it has been for the better. Especially since the days of Galileo and Newton, math has nurtured science. Rigorous mathematical methods have secured science’s fidelity to fact and conferred a timeless reliability to its findings.