A neural implant can translate brain activity into sentences
Decoding the brain’s instructions to vocal tracts could someday help the speechless speak

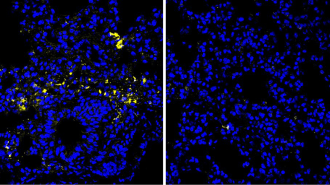
DECODING SPEECH Scientists have transformed brain signals, captured by this grid of electrodes designed to record brain activity, into synthesized sentences. The technique could one day help people who can’t speak communicate.
UCSF
To communicate, people unable to talk often rely on small eye movements to spell out words, a painstakingly slow process. Now, using signals picked up by a brain implant, scientists have pulled entire sentences from the brain.
Some of these reconstructed words, spoken aloud by a virtual vocal cord, are a little garbled. But overall, the sentences are understandable, researchers from the University of California, San Francisco report in the April 25 Nature.
Creating the audible synthetic sentences required years of analysis after brain signals were recorded, and the technique is not ready to be used outside of a lab. Still, the work shows “that just using the brain, it is possible to decode speech,” says UCSF speech scientist Gopala Anumanchipalli.
The technology described in the new study holds promise for ultimately restoring people’s abilities to speak fluently, says Frank Guenther, a speech neuroscientist at Boston University. “It’s hard to overstate the importance of that to these people…. It’s incredibly isolating and practically nightmarish to not be able to communicate needs or socially connect.”
Existing speech aids that rely on spelling words are tedious, often producing about 10 words a minute. Earlier studies have used brain signals to decode smaller bits of speech, such as vowels or words, but with a more limited vocabulary than the current work.
Along with neurosurgeon Edward Chang and bioengineer Josh Chartier, Anumanchipalli studied five people who had grids of electrodes temporarily implanted in the brain as part of epilepsy treatments. Because these people could talk, researchers could record brain activity as participants spoke sentences. The team then mapped the brain signals that control the lips, tongue, jaw and larynx to the actual movements of the vocal tract as these people spoke. That allowed the scientists to create a unique virtual vocal tract for each person.
Decoding speech
Scientists have transformed brain signals, captured by this grid of electrodes designed to record brain activity, into synthesized sentences. The technique could one day help people who can’t speak communicate.
Next, the researchers translated the virtual movements of participants’ artificial vocal tracts into sounds. Using this virtual tool “enhanced the speech and made it sound more natural,” Chartier says. About 70 percent of these reconstructed words were understandable by listeners who were asked to choose the words that they heard from a list of possibilities. For instance, when the synthesized voice said, “Get a calico cat to keep the rodents away,” a listener heard, “The calico cat to keep the rabbits away.” Overall, some sounds came out well, such as “sh.” Others, such as “buh” and “puh,” sounded mushier.
To work, the technique depended on knowing how a person moves the vocal tract. But those movements won’t exist in many people who are unable to talk, such as those with a brain stem stroke, vocal tract injuries or Lou Gehrig’s disease.
“By far, the biggest hurdle is how are you going to build a decoder in the first place when you don’t have any example speech to build it on?” says Marc Slutzky, a neurologist and neural engineer at Northwestern University’s Feinberg School of Medicine in Chicago.
In some tests, the researchers found that the algorithms used in the second stage of the process — translating the virtual vocal tract movements into sounds — were similar enough from person to person that they could be reused across different people, possibly even those who can’t talk.
But so far, the first step of the process — mapping brain activity to a person’s vocal tract movements — seems to be more idiosyncratic. Finding a way to relate those personalized brain signals to their desired vocal tract movements will be a challenge in people unable to move, the scientists say.