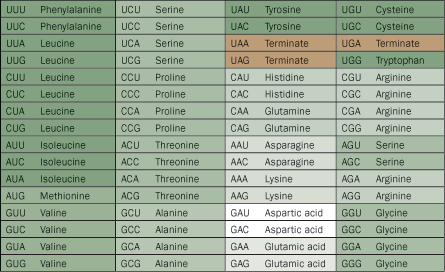
RELATED NEIGHBORS | The genetic code used by all life on Earth maps 64 three-letter words to 20 corresponding amino acids and a stop signal, which serves as a punctuation mark. Since similar amino acids are coded by similar three-letter words (degree of shading represents similarity, with “stop” signals in brown”), some researchers think a pressure to reduce the havoc brought about by errors may have been an important driving force during the code’s early development.
Log in
Subscribers, enter your e-mail address for full access to the Science News archives and digital editions.