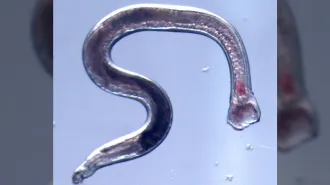
LOCK PICKING Searching genetic genealogy databases may allow the identification of almost anyone, even if their DNA is anonymous.
jxfzsy/istock.com, adapted by E. Otwell
Protecting the anonymity of publicly available genetic data, including DNA donated to research projects, may be impossible.
About 60 percent of people of European descent who search genetic genealogy databases will find a match with a relative who is a third cousin or closer, a new study finds. The result suggests that with a database of about 3 million people, police or anyone else with access to DNA data can figure out the identity of virtually any American of European descent, Yaniv Erlich and colleagues report online October 11 in Science.
Erlich, the chief science officer of the consumer genetic testing company MyHeritage, and colleagues examined his company’s database and that of the public genealogy site GEDMatch, each containing data from about 1.2 million people. Using DNA matches to relatives, along with family tree information and some basic demographic data, scientists estimate that they could narrow the identity of an anonymous DNA owner to just one or two people.
Recent cases identifying suspects in violent crimes through DNA searches of GEDMatch, such as the Golden State Killer case (SN Online: 4/29/18), have raised privacy concerns (SN Online: 6/7/18). And the same process used to find rape and murder suspects can also identify people who have donated anonymous DNA for genetic and medical research studies, the scientists say.
Genetic data used in research is stripped of information like names, ages and addresses, and can’t be used to identify individuals, government officials have said. But “that’s clearly untrue,” as Erlich and colleagues have demonstrated, says Rori Rohlfs, a statistical geneticist at San Francisco State University, who was not involved in the study.
Using genetic genealogy techniques that mirror searches for the Golden State Killer and suspects in at least 15 other criminal cases, Erlich’s team identified a woman who participated anonymously in the 1000 Genomes project. That project cataloged genetic variants in about 2,500 people from around the world.
Erlich’s team pulled the woman’s anonymous data from the publicly available 1000 Genomes database. The researchers then created a DNA profile similar to the ones generated by consumer genetic testing companies such as 23andMe and AncestryDNA (SN: 6/23/18, p.14) and uploaded that profile to GEDMatch.
A search turned up matches with two distant cousins, one from North Dakota and one from Wyoming. The cousins also shared DNA indicating that they had a common set of ancestors four to six generations ago. Building on some family tree information already collected by those cousins, researchers identified the ancestral couple and filled in hundreds of their descendants, looking for a woman who matched the age and other publicly available demographic data of the 1000 Genomes participant.
It took a day to find the right person.
That example suggests scientists that need to reconsider whether they can guarantee research participants anonymity if genetic data are publicly shared, Rohlfs says.
In reality, though, identifying a person from a DNA match with a distant relative is much harder than it appears, and requires a lot of expertise and gumshoe work, Ellen Greytak says. She is the director of bioinformatics at Parabon NanoLabs, a company in Reston, Va., that has helped close at least a dozen criminal cases since May using genetic genealogy searches. “The gulf between a match and identification is absolutely massive,” she says.
The company has also found that people of European descent often have DNA matches to relatives in GEDMatch. But tracking down a single suspect from those matches is often confounded by intermarriages, adoptions, aliases, cases of misidentified or unknown parentage and other factors, says CeCe Moore, a genealogist who spearheads Parabon’s genetic genealogy service.
“The study demonstrates the power of genetic genealogy in a theoretical way,” Moore says, “but doesn’t fully capture the challenges of the work in practice.” For instance, Erlich and colleagues already had some family tree information from the 1000 Genome woman’s relatives, “so they had a significant head start.”
Erlich’s example might be an oversimplification, Rohlfs says. The researchers made rough estimates and assumptions that are not perfect, but the conclusion is solid, she says. “Their work is approximate, but totally reasonable.” And that conclusion that almost anyone can be identified from DNA should spark public discussion about how DNA data should be used for law enforcement and research, she says.