MONTREAL — Eavesdroppers might not have to lip-read to listen in on a far-off conversation. Using a high-speed camera pointed at the throat, scientists can decipher a person’s words without relying on a microphone.
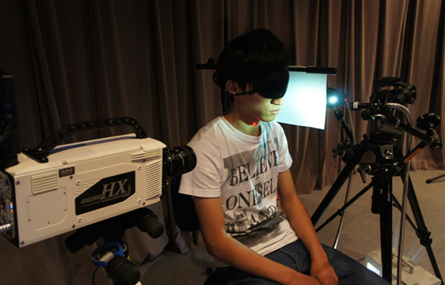
By snapping thousands of images per second, researchers recorded every wavering wobble of neck flesh that accompanied sounds floating out from a person’s voice box. A computer program then turned the recorded skin vibrations into sound waves, Yasuhiro Oikawa of Waseda University in Tokyo reported June 3 at the International Congress on Acoustics.
Standard lip-reading software tracks lip twitches, tongue waggles and jaw motions as a person’s mouth forms a word. Some programs are sophisticated enough to recognize different languages, but the computer doesn’t offer much more than a transcript, Oikawa said.
Textual information is important, but so is intonation, pitch and volume, he said. “We get a sense of a speaker’s feeling from their voice.”
Microphones have problems, too: A mic often records too much background noise — especially outside, where the whooshing whistle of the wind or the loud plop of a raindrop can drown out a person’s voice.
So Oikawa and colleagues looked for a new way to record speech that could capture vocal tones.
Using a high-speed camera, the researchers zoomed in on the throats of two volunteers and recorded them saying the Japanese word tawara, which means straw bale or bag. The team’s camera recorded at 10,000 frames per second; the typical rate for a movie projected in a theater is 24.
At the same time, Oikawa’s team recorded the volunteers’ words with a standard microphone and a vibrometer, a device that measured vibrations of their skin.
The throat vibrations recorded by the camera looked similar to the vibrations picked up by the microphone and the vibrometer, Oikawa said.
And when the team ran the camera’s vibration data through a computer program, they could reconstruct the volunteers’ voices well enough to understand the word spoken, Oikawa said. Before the end of the year, he thinks he may be able to record and play back a full sentence using the high-speed camera technique.
The technique should allow scientists to hear words even if there’s a lot of background noise, said physicist Claire Prada of the National Center for Scientific Research in Paris. The work is promising, she said, but “it’s still just proof of principle.”
But other scientists at the presentation seemed skeptical. Mechanical engineer Weikang Jiang of Shanghai Jiao Tong University in China noted that Oikawa did not play audio of reconstructed voices; instead he showed pictures of the sound waves. Jiang praised the work’s novelty, but said, “He didn’t show us the results.”
Next, Oikawa wants to focus the camera on a person’s cheeks to look for more skin spots that jiggle during speech. Analyzing more vibrating areas could give researchers extra info about a person’s voice, and that could improve voice reconstruction.