A visit to the supermarket can present a shopper with a bewildering array of choices. For ice cream alone, the consumer faces a variety of brands, flavors, container sizes, and types (fat-free versus low-fat versus premium, and so on).
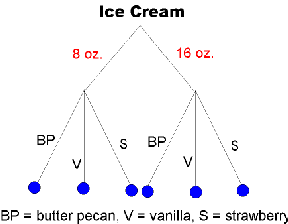


At the same time, deciding which items to stock is a formidable problem for retailers. They have a limited amount of shelf space, yet the number of different products in a particular category can be overwhelming.