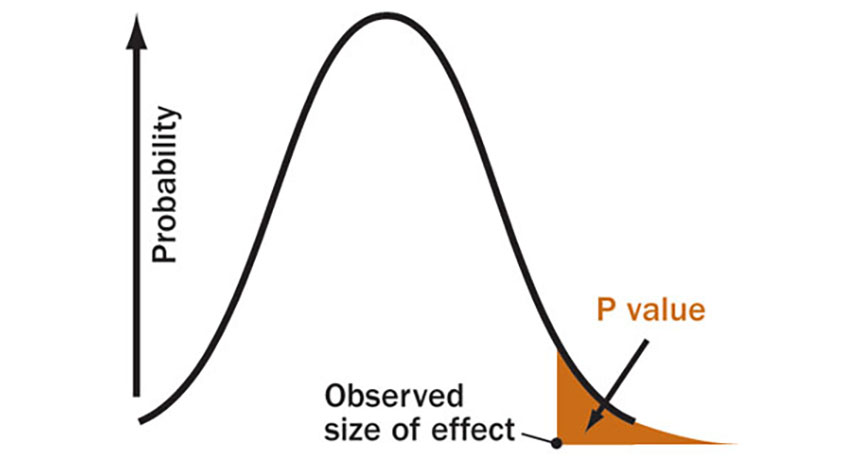
WORTHLESS A P value is the probability of recording a result as large or more extreme than the observed data if there is in fact no real effect. P values are not a reliable measure of evidence.
S. Goodman, adapted by A. Nandy
Second of two parts (read part 1)
Statistics is to science as steroids are to baseball. Addictive poison. But at least baseball has attempted to remedy the problem. Science remains mostly in denial.
True, not all uses of statistics in science are evil, just as steroids are sometimes appropriate medicines. But one particular use of statistics — testing null hypotheses — deserves the same fate with science as Pete Rose got with baseball. Banishment.
Numerous experts have identified statistical testing of null hypotheses — the staple of scientific methodology — as a prime culprit in rendering many research findings irreproducible and, perhaps more often than not, erroneous. Many factors contribute to this abysmal situation. In the life sciences, for instance, problems with biological agents and reference materials are a major source of irreproducible results, a new report in PLOS Biology shows. But troubles with “data analysis and reporting” are also cited. As statistician Victoria Stodden recently documented, a variety of statistical issues lead to irreproducibility. And many of those issues center on null hypothesis testing. Rather than furthering scientific knowledge, null hypothesis testing virtually guarantees frequent faulty conclusions.
“For more than half a century, distinguished scholars have published damning critiques of null hypothesis significance testing and have described the damage it does,” psychologist Geoff Cumming wrote last year in Psychological Science. “Very few defenses of null hypothesis significance testing have been attempted; it simply persists.”
A null hypothesis assumes that a factor being tested produces no effect (or an effect no different from some other factor). If experimental data are sufficiently unlikely (given the no-effect assumption), scientists reject the null hypothesis and infer that there is an effect. They call such a result “statistically significant.”
Statistical significance has nothing to do with actual significance, though. A statistically significant effect can be trivially small. Or even completely illusory.
Cumming, of the Statistical Cognition Laboratory at La Trobe University in Victoria, Australia, advocates a “new statistics” that dumps null hypothesis testing in favor of saner methods. “We need to make substantial changes to how we usually carry out research,” he declares. In his Psychological Science paper (as well as in a 2012 book), he describes an approach that focuses on three priorities: estimating the magnitude of an effect, quantifying the precision of that estimate, and combining results from multiple studies to make those estimates more precise and reliable.
Implementing Cumming’s new statistics will require more than just blog posts lamenting the problems. Someone needs to promote the recommendations that he and other worried researchers have identified. As in a Top 10 list. And since the situation is urgent, appended right here and now are my Top 10 ways to save science from its statistical self:
10. Ban P values
Statistical significance tests are commonly calculated using P values (the probability of observing the measured data — or data even more extreme — if the null hypothesis is correct). It has been repeatedly demonstrated that P values are essentially worthless as a measure of evidence. For one thing, different samples from the same dataset can yield dramatically different P values. “Any calculated value of P could easily have been very different had we merely taken a different sample, and therefore we should not trust any P value,” writes Cumming.
On occasion some journal editors have banned P values, most recently in Basic and Applied Social Psychology. Ideally there would be an act of Congress (and a United Nations resolution) condemning P values and relegating them to the same category as chemical weapons and smoking in airplanes.
9. Emphasize estimation
A major flaw with yes-or-no null hypothesis tests is that the right answer is almost always “no.” In other words, a null hypothesis is rarely true. Seldom would anything worth testing have an absolutely zero effect. With enough data, you can rule out virtually any null hypothesis, as psychologists John Kruschke and Torrin Liddell of Indiana University point out in a recent paper.
The important question is not whether there’s an effect, but how big the effect is. And null hypothesis testing doesn’t help with that. “The result of a hypothesis test reveals nothing about the magnitude of the effect or the uncertainty of its estimate, which are the key things we should want to know,” Kruschke and Liddell assert.
Cumming advocates using statistics to estimate actual effect magnitude in preference to null hypothesis testing, which “prompts us to see the world as black or white, and to formulate our research aims and make our conclusions in dichotomous terms — an effect … exists or it does not.”
8. Rethink confidence intervals
Estimating an effect’s magnitude isn’t enough — you need to know how precise that estimate is. Such precision is commonly expressed by a confidence interval, similar to an opinion poll’s margin of error. Confidence intervals are already often reported, but they are often not properly examined to infer an effect’s true importance. A result trumpeted as “statistically significant,” for instance, may have a confidence interval covering such a wide range that the actual effect size could be either tiny or titanic. And when a large confidence interval overlaps with zero effect, researchers typically conclude that there is no effect, even though the confidence interval is so large that a sizable effect should not be ruled out.
“Researchers must be disabused of the false belief that if a finding is not significant, it is zero,” Kruschke and Liddell write. “This belief has probably done more than any of the other false beliefs about significance testing to retard the growth of cumulative knowledge in psychology.” And no doubt in other fields as well.
But properly calculated and interpreted, confidence intervals are useful measures of precision, Cumming writes. It’s just important that “we should not lapse back into dichotomous thinking by attaching any particular importance to whether a value of interest lies just inside or just outside our confidence interval.”
7. Improve meta-analyses
As Kruschke and Liddell note, each sample from a population will produce a different estimate of an effect. So no one study ever provides a thoroughly trustworthy result. “Therefore, we should combine the results of all comparable studies to derive a more stable estimate of the true underlying effect,” Kruschke and Liddell conclude. Combining studies in a “meta-analysis” is already common practice in many fields, such as biomedicine, but the conditions required for legitimate (and reliable) meta-analysis are seldom met. For one thing, it’s important to acquire results from every study on the issue, but many are unpublished and unavailable. (Studies that find a supposed effect are more likely to get published than those that don’t, biasing meta-analyses toward validating effects that aren’t really there.)
A meta-analysis of multiple studies can in principle sharpen the precision of an effect’s estimated size. But most meta-analyses typically create very large samples in order that small alleged effects can achieve statistical significance in a null hypothesis test. A better approach, Cumming argues, is to emphasize estimation and forget hypothesis testing.
“Meta-analysis need make no use of null hypothesis statistical testing,” he writes. “Indeed, NHST has caused some of its worst damage by distorting the results of meta-analysis.”
6. Create a Journal of Statistical Shame
OK, maybe it could have a nicer name, but a journal devoted to analyzing the statistical methods and reasoning in papers published elsewhere would help call attention to common problems. In particular, any studies that get widespread media attention could be analyzed for statistical and methodological flaws. Supposedly a journal’s editorial processes and peer review already monitor such methodological issues before publication. Supposedly.
5. Better guidelines for scientists and journal editors
Recently several scientific societies and government agencies have recognized the need to do something about the unsavory statistical situation. In May, the National Science Foundation’s advisory committee on social, behavioral and economic sciences issued a report on replicability in science. Its recommendations mostly suggested studying the issue some more. And the National Institutes of Health has issued “Principles and Guidelines for Reporting Preclinical Research.” But the NIH guidelines are general enough to permit the use of the same flawed methods. Journals should, for instance, “require that statistics be fully reported in the paper, including the statistical test used … and precision measures” such as confidence intervals. But it doesn’t help much to report the statistics fully if the statistical methods are bogus to begin with.
More to the point, a recent document from the Society for Neuroscience specifically recommends against “significance chasing” and advocates closer attention to issues in experimental design and data analysis that can sabotage scientific rigor.
One especially pertinent recommendation, emphasized in a report published June 26 in Science, is “data transparency.” That can mean many things, including sharing of experimental methods and the resulting data so other groups can reproduce experimental findings. Sharing of computer code is also essential in studies relying on high-powered computational analysis of “big data.”
4. Require preregistration of study designs
An issue related to transparency, also emphasized in the guidelines published in Science, is the need for registering experimental plans in advance. Many of science’s problems stem from shoddy statistical practices, such as choosing what result to report after you have tested a bunch of different things and found one that turned out to be statistically significant. Funders and journals should require that all experiments be preregistered, with clear statements about what is being tested and how the statistics will be applied. (In most cases, for example, it’s important to specify in advance how big your sample will be, disallowing the devious technique of continuing to enlarge the sample until you see a result you like.) Such a preregistration program has already been implemented for clinical trials. And websites to facilitate preregistration more generally already exist, such as Open Science Framework.
3. Promote better textbooks
Guidelines helping scientists avoid some of the current system’s pitfalls can help, but they fall short of radically revising the whole research enterprise. A more profound change will require better brainwashing of scientists when they are younger. Therefore, it would be a good idea to attack the problem at its source: textbooks.
Science’s misuse of statistics originates with traditional textbooks, which have taught flawed methods, such as the use of P values, for decades. One new introductory textbook is in the works from Cumming, possibly to appear next year. Many other useful texts exist, including some devoted to Bayesian methods, which Kruschke and Liddell argue are the best way to implement Cumming’s program to kill null hypotheses. But getting the best texts to succeed in a competitive marketplace will require some sort of promotional effort. Perhaps a consortium of scientific societies could convene a committee to create a new text, or at least publicize those that would do more to solve science’s problems than perpetuate them.
2. Alter the incentive structure
Science has ignored the cancer on its credibility for so long because the incentives built into the system pose a cultural barrier to change. Research grants, promotion and tenure, fame and fortune are typically achieved through publishing a lot of papers. Funding agencies, journal editors and promotion committees all like quantitative metrics to make their decision making easy (that is, requiring little thought). The current system is held hostage by those incentives.
In another article in the June 26 Science, a committee of prominent scientific scholars argues that quality should be emphasized over quantity. “We believe that incentives should be changed so that scholars are rewarded for publishing well rather than often,” the scholars wrote. In other words, science needs to make the commitment to intelligent assessment over mindless quantification.
1. Rethink media coverage of science
One of the incentives driving journals — and therefore scientists — is the desire for media attention. In recent decades journals have fashioned their operations to promote media coverage of the papers they publish — often to the detriment of enforcing rigorous scientific standards for the papers they publish. Science journalists have been happy (well, not all of us) to participate in this conspiracy. As I’ve written elsewhere, the flaws in current statistical practices promote publication of papers trumpeting the “first” instance of a finding, results of any sort in “hot” research fields, or findings likely to garner notice because they are “contrary to previous belief.” These are precisely the qualities that journalists look for in reporting the news. Consequently many research findings reported in the media turn out to be wrong — even though the journalists are faithfully reporting what scientists have published.
As one prominent science journalist once articulated this situation to me, “The problem with science journalism is science.” So maybe it’s time for journalists to strike back, and hold science accountable to the standards it supposedly stands for. I’ll see what I can do.
Follow me on Twitter: @tom_siegfried





