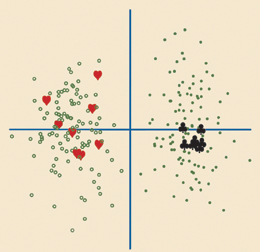
AUTHOR SWITCH. The modern cover of The Royal Book of Oz lists Ruth Plumly Thompson, not L. Frank Baum, as the author. A new mathematical analysis supports that attribution. Dover PublicationsDISTINCT STYLES. Points representing texts by L. Frank Baum (black dots) are far separated from those of texts by Ruth Plumly Thompson (open circles).
Log in
Subscribers, enter your e-mail address for full access to the Science News archives and digital editions.