The gene sequencing future is here
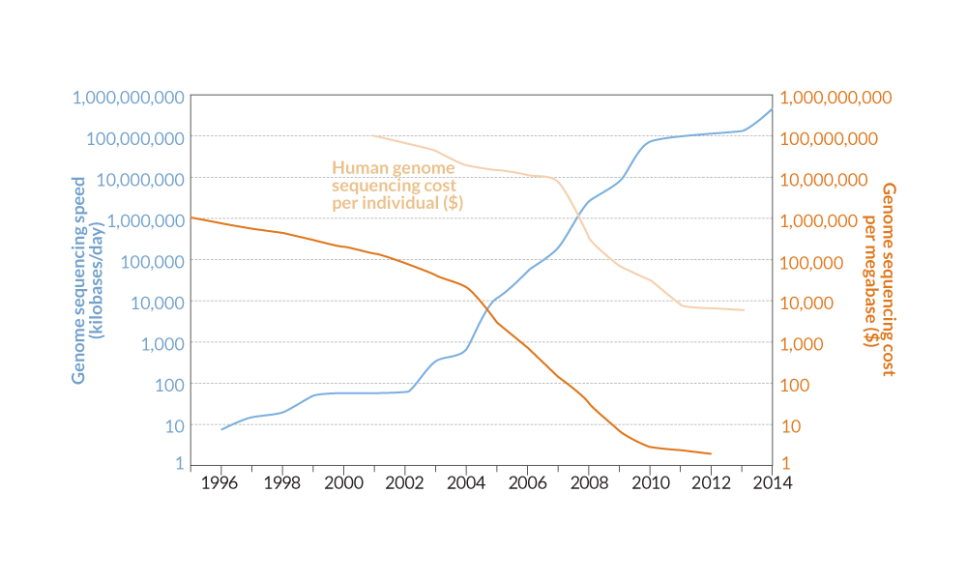
BIG DATA Improvements in genome sequencing technology over the past two decades has boosted the speed and cut the cost of decoding DNA.
E. Otwell
As recently as the 1980s, scientists collected genetic data by laboriously tracking the diffusion of DNA molecules through slabs of gel. Now researchers stand by as machines gush billions of letters of DNA code a day, and struggle to cope with the data deluge.