Data-driven crime prediction fails to erase human bias
Poor, minority communities flagged as drug crime trouble spots in case study

BIG DATA DOESN’T PAY Software programs that use police records to predict crime hot spots may result in police unfairly targeting low-income and minority communities, a new study shows.
artolympic/istockphoto
Big data is everywhere these days and police departments are no exception. As law enforcement agencies are tasked with doing more with less, many are using predictive policing tools. These tools feed various data into algorithms to flag people likely to be involved with future crimes or to predict where crimes will occur.
In the years since Time magazine named predictive policing as one of 2011’s best 50 inventions of the year, its popularity has grown. Twenty U.S. cities, including Chicago, Atlanta, Los Angeles and Seattle are using a predictive policing system, and several more are considering it. But with the uptick in use has come a growing chorus of caution. Community activists, civil rights groups and even some skeptical police chiefs have raised concerns that predictive data approaches may unfairly target some groups of people more than others.
New research by statistician Kristian Lum provides a telling case study. Lum, who leads the policing project at the San Francisco-based Human Rights Data Analysis Group, looked at how the crime-mapping program PredPol would perform if put to use in Oakland, Calif. PredPol, which purports to “eliminate profiling concerns,” takes data on crime type, location and time and feeds it into a machine-learning algorithm. The algorithm, originally based on predicting seismic activity after an earthquake, trains itself with the police crime data and then predicts where future crimes will occur.
Lum was interested in bias in the crime data — not political or racial bias, just the ordinary statistical kind. While this bias knows no color or socioeconomic class, Lum and her HRDAG colleague William Isaac demonstrate that it can lead to policing that unfairly targets minorities and those living in poorer neighborhoods.
By applying the algorithm to 2010 data on drug crime reports for Oakland, the researchers generated a predicted rate of drug crime on a map of the city for every day of 2011. The researchers then compared the data used by the algorithm — drug use documented by the police — with a record of overall drug use, whether recorded or not. This ground-truthing came from taking public health data from the 2011 National Survey on Drug Use and Health and demographic data from the city of Oakland to derive an estimate of drug use for all city residents.
Story continues below maps
Wheredunit
Drug use in Oakland is probably fairly widespread (left) based on estimates derived in part from the 2011 National Survey on Drug Use and Health. But police records of drug reports and crimes are concentrated in areas that are largely nonwhite and low-income (right).
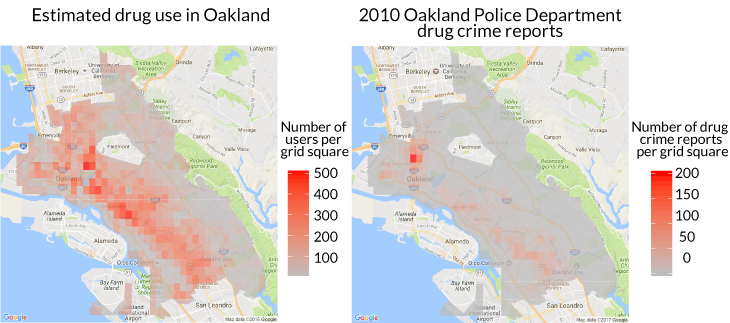
In this public health-based map, drug use is widely distributed across the city. In the predicted drug crime map, it is not. Instead, drug use deemed worthy of police attention is concentrated in neighborhoods in West Oakland and along International Boulevard, two predominately low-income and nonwhite areas.
Predictive policing approaches are often touted as eliminating concerns about police profiling. But rather than correcting bias, the predictive model exacerbated it, Lum said during a panel on data and crime at the American Association for the Advancement of Science annual meeting in Boston in February. While estimates of drug use are pretty even across race, the algorithm would direct Oakland police to locations that would target black people at roughly twice the rate of whites. A similar disparity emerges when analyzing by income group: Poorer neighborhoods get targeted.
Shifting target
While drug use estimated from public health data is roughly equivalent across racial classifications (top), police using a predictive policing algorithm in Oakland, Calif., would target black people at roughly twice the rate of whites (bottom).

And a troubling feedback loop emerges when police are sent to targeted locations. If police find slightly more crime in an area because that’s where they’re concentrating patrols, these crimes become part of the dataset that directs where further patrolling should occur. Bias becomes amplified, hot spots hotter.
There’s nothing wrong with PredPol’s algorithm, Lum notes. Machine learning algorithms learn patterns and structure in data. “The algorithm did exactly what we asked; it learned patterns in the data,” she says. The danger is in thinking that predictive policing will tell you about patterns in the occurrence of crime. It’s really telling you about patterns in police records.
Police aren’t tasked with collecting random samples, nor should they be, says Lum. And that’s all the more reason why departments should be transparent and vigilant about how they use their data. In some ways, PredPol-guided policing isn’t so different from old-fashioned pins on a map.
For her part, Lum would prefer that police stick to these timeworn approaches. With pins on a map, the what, why and where of the data are very clear. The black box of an algorithm, on the other hand, lends undue legitimacy to the police targeting certain locations while simultaneously removing accountability. “There’s a move toward thinking machine learning is our savior,” says Lum. “You hear people say, “A computer can’t be racist.’”
The use of predictive policing may be costly, both literally and figuratively. The software programs can run from $20,000 to up to $100,000 per year for larger cities. It’s harder to put numbers on the human cost of over-policing, but the toll is real. Increased police scrutiny can lead to poor mental health outcomes for residents and undermine relationships between police and the communities they serve. Big data doesn’t help when it’s bad data.







