Machines are getting schooled on fairness
Machine-learning programs can introduce biases that may harm job seekers, loan applicants and more

FAIR-MINDED MACHINES There is more than one approach to trimming unintended biases from the machines that we are teaching to make more and more of our decisions.
Alex NaBaum
You’ve probably encountered at least one machine-learning algorithm today. These clever computer codes sort search engine results, weed spam e-mails from inboxes and optimize navigation routes in real time. People entrust these programs with increasingly complex — and sometimes life-changing — decisions, such as diagnosing diseases and predicting criminal activity.
Machine-learning algorithms can make these sophisticated calls because they don’t simply follow a series of programmed instructions the way traditional algorithms do. Instead, these souped-up programs study past examples of how to complete a task, discern patterns from the examples and use that information to make decisions on a case-by-case basis.
Unfortunately, letting machines with this artificial intelligence, or AI, figure things out for themselves doesn’t just make them good critical “thinkers,” it also gives them a chance to pick up biases.
Investigations in recent years have uncovered several ways algorithms exhibit discrimination. In 2015, researchers reported that Google’s ad service preferentially displayed postings related to high-paying jobs to men. A 2016 ProPublica investigation found that COMPAS, a tool used by many courtrooms to predict whether a criminal will break the law again, wrongly predicted that black defendants would reoffend nearly twice as often as it made that wrong prediction for whites. The Human Rights Data Analysis Group also showed that the crime prediction tool PredPol could lead police to unfairly target low-income, minority neighborhoods (SN Online: 3/8/17). Clearly, algorithms’ seemingly humanlike intelligence can come with humanlike prejudices.
“This is a very common issue with machine learning,” says computer scientist Moritz Hardt of the University of California, Berkeley. Even if a programmer designs an algorithm without prejudicial intent, “you’re very likely to end up in a situation that will have fairness issues,” Hardt says. “This is more the default than the exception.”
Story contines below graphic
Prediction prejudice
A machine-learning program trained on drug crime data from Oakland, Calif., would offer a skewed perspective on where to send police officers. Reported drug crimes came mainly from nonwhite and low-income neighborhoods in 2010 (left). But 2011 public health data suggest drug use was much more widespread (right).

Developers may not even realize a program has taught itself certain prejudices. This problem gets down to what is known as a black box issue: How exactly is an algorithm reaching its conclusions? Since no one tells a machine-learning algorithm exactly how to do its job, it’s often unclear — even to the algorithm’s creator — how or why it ends up using data the way it does to make decisions.
Several socially conscious computer and data scientists have recently started wrestling with the problem of machine bias. Some have come up with ways to add fairness requirements into machine-learning systems. Others have found ways to illuminate the sources of algorithms’ biased behavior. But the very nature of machine-learning algorithms as self-taught systems means there’s no easy fix to make them play fair.
Learning by example
In most cases, machine learning is a game of algorithm see, algorithm do. The programmer assigns an algorithm a goal — say, predicting whether people will default on loans. But the machine gets no explicit instructions on how to achieve that goal. Instead, the programmer gives the algorithm a dataset to learn from, such as a cache of past loan applications labeled with whether the applicant defaulted.
The algorithm then tests various ways to combine loan application attributes to predict who will default. The program works through all of the applications in the dataset, fine-tuning its decision-making procedure along the way. Once fully trained, the algorithm should ideally be able to take any new loan application and accurately determine whether that person will default.
The trouble arises when training data are riddled with biases that an algorithm may incorporate into its decisions. For instance, if a human resources department’s hiring algorithm is trained on historical employment data from a time when men were favored over women, it may recommend hiring men more often than women. Or, if there were fewer female applicants in the past, then the algorithm has fewer examples of those applications to learn from, and it may not be as accurate at judging women’s applications.
At first glance, the answer seems obvious: Remove any sensitive features, such as race or sex, from the training data. The problem is, there are many ostensibly nonsensitive aspects of a dataset that could play proxy for some sensitive feature. Zip code may be strongly related to race, college major to sex, health to socioeconomic status.
And it may be impossible to tell how different pieces of data — sensitive or otherwise — factor into an algorithm’s verdicts. Many machine-learning algorithms develop deliberative processes that involve so many thousands of complex steps that they’re impossible for people to review.
Creators of machine-learning systems “used to be able to look at the source code of our programs and understand how they work, but that era is long gone,” says Simon DeDeo, a cognitive scientist at Carnegie Mellon University in Pittsburgh. In many cases, neither an algorithm’s authors nor its users care how it works, as long as it works, he adds. “It’s like, ‘I don’t care how you made the food; it tastes good.’ ”
But in other cases, the inner workings of an algorithm could make the difference between someone getting parole, an executive position, a mortgage or even a scholarship. So computer and data scientists are coming up with creative ways to work around the black box status of machine-learning algorithms.
Setting algorithms straight
Some researchers have suggested that training data could be edited before given to machine-learning programs so that the data are less likely to imbue algorithms with bias. In 2015, one group proposed testing data for potential bias by building a computer program that uses people’s nonsensitive features to predict their sensitive ones, like race or sex. If the program could do this with reasonable accuracy, the dataset’s sensitive and nonsensitive attributes were tightly connected, the researchers concluded. That tight connection was liable to train discriminatory machine-learning algorithms.
To fix bias-prone datasets, the scientists proposed altering the values of whatever nonsensitive elements their computer program had used to predict sensitive features. For instance, if their program had relied heavily on zip code to predict race, the researchers could assign fake values to more and more digits of people’s zip codes until they were no longer a useful predictor for race. The data could be used to train an algorithm clear of that bias — though there might be a tradeoff with accuracy.
On the flip side, other research groups have proposed de-biasing the outputs of already-trained machine-learning algorithms. In 2016 at the Conference on Neural Information Processing Systems in Barcelona, Hardt and colleagues recommended comparing a machine-learning algorithm’s past predictions with real-world outcomes to see if the algorithm was making mistakes equally for different demographics. This was meant to prevent situations like the one created by COMPAS, which made wrong predictions about black and white defendants at different rates. Among defendants who didn’t go on to commit more crimes, blacks were flagged by COMPAS as future criminals more often than whites. Among those who did break the law again, whites were more often mislabeled as low-risk for future criminal activity.
For a machine-learning algorithm that exhibits this kind of discrimination, Hardt’s team suggested switching some of the program’s past decisions until each demographic gets erroneous outputs at the same rate. Then, that amount of output muddling, a sort of correction, could be applied to future verdicts to ensure continued even-handedness. One limitation, Hardt points out, is that it may take a while to collect a sufficient stockpile of actual outcomes to compare with the algorithm’s predictions.
Fix it
To try to remove bias, researchers altered the training data used to teach three algorithms: an income predictor, a credit scorer and a judge of promotion-worthiness. For all three, the change could bring the ratio of outputs for different demographics up to 1 (the mark of complete balance between groups). However, the data-fixing decreased accuracy for credit scores and promotion decisions.
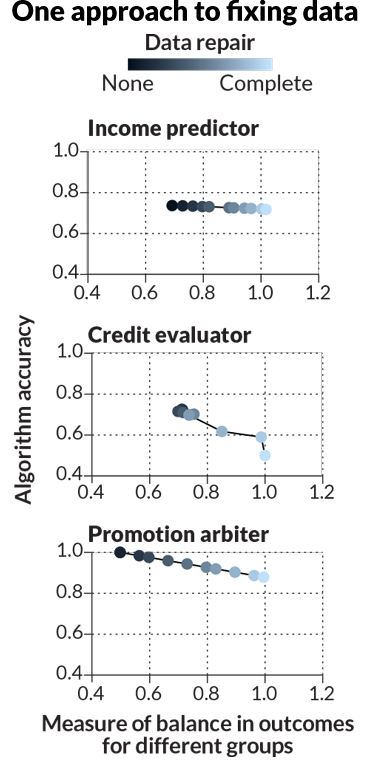
Source: M. Feldman et al/arXiv.org 2015
A third camp of researchers has written fairness guidelines into the machine-learning algorithms themselves. The idea is that when people let an algorithm loose on a training dataset, they don’t just give the software the goal of making accurate decisions. The programmers also tell the algorithm that its outputs must meet some certain standard of fairness, so it should design its decision-making procedure accordingly.
In April, computer scientist Bilal Zafar of the Max Planck Institute for Software Systems in Kaiserslautern, Germany, and colleagues proposed that developers add instructions to machine-learning algorithms to ensure they dole out errors to different demographics at equal rates — the same type of requirement Hardt’s team set. This technique, presented in Perth, Australia, at the International World Wide Web Conference, requires that the training data have information about whether the examples in the dataset were actually good or bad decisions. For something like stop-and-frisk data, where it’s known whether a frisked person actually had a weapon, the approach works. Developers could add code to their program that tells it to account for past wrongful stops.
Zafar and colleagues tested their technique by designing a crime-predicting machine-learning algorithm with specific nondiscrimination instructions. The researchers trained their algorithm on a dataset containing criminal profiles and whether those people actually reoffended. By forcing their algorithm to be a more equal opportunity error-maker, the researchers were able to reduce the difference between how often blacks and whites who didn’t recommit were wrongly classified as being likely to do so: The fraction of people that COMPAS mislabeled as future criminals was about 45 percent for blacks and 23 percent for whites. In the researchers’ new algorithm, misclassification of blacks dropped to 26 percent and held at 23 percent for whites.
These are just a few recent additions to a small, but expanding, toolbox of techniques for forcing fairness on machine-learning systems. But how these algorithmic fix-its stack up against one another is an open question since many of them use different standards of fairness. Some require algorithms to give members of different populations certain results at about the same rate. Others tell an algorithm to accurately classify or misclassify different groups at the same rate. Still others work with definitions of individual fairness that require algorithms to treat people who are similar barring one sensitive feature similarly. To complicate matters, recent research has shown that, in some cases, meeting more than one fairness criterion at once can be impossible.
“We have to think about forms of unfairness that we may want to eliminate, rather than hoping for a system that is absolutely fair in every possible dimension,” says Anupam Datta, a computer scientist at Carnegie Mellon.
Still, those who don’t want to commit to one standard of fairness can perform de-biasing procedures after the fact to see whether outputs change, Hardt says, which could be a warning sign of algorithmic bias.
Show your work
But even if someone discovered that an algorithm fell short of some fairness standard, that wouldn’t necessarily mean the program needed to be changed, Datta says. He imagines a scenario in which a credit-classifying algorithm might give favorable results to some races more than others. If the algorithm based its decisions on race or some race-related variable like zip code that shouldn’t affect credit scoring, that would be a problem. But what if the algorithm’s scores relied heavily on debt-to-income ratio, which may also be associated with race? “We may want to allow that,” Datta says, since debt-to-income ratio is a feature directly relevant to credit.
Of course, users can’t easily judge an algorithm’s fairness on these finer points when its reasoning is a total black box. So computer scientists have to find indirect ways to discern what machine-learning systems are up to.
One technique for interrogating algorithms, proposed by Datta and colleagues in 2016 in San Jose, Calif., at the IEEE Symposium on Security and Privacy, involves altering the inputs of an algorithm and observing how that affects the outputs. “Let’s say I’m interested in understanding the influence of my age on this decision, or my gender on this decision,” Datta says. “Then I might be interested in asking, ‘What if I had a clone that was identical to me, but the gender was flipped? Would the outcome be different or not?’ ” In this way, the researchers could determine how much individual features or groups of features affect an algorithm’s judgments. Users performing this kind of auditing could decide for themselves whether the algorithm’s use of data was cause for concern. Of course, if the code’s behavior is deemed unacceptable, there’s still the question of what to do about it. There’s no “So your algorithm is biased, now what?” instruction manual.
Story continues below graph
Inside AI
Computer scientist Anupam Datta and colleagues devised a way to show how various dataset features influence an algorithm’s output. In an algorithm that predicts a person’s likelihood of committing crimes, race had a role but carried less weight than drug history.
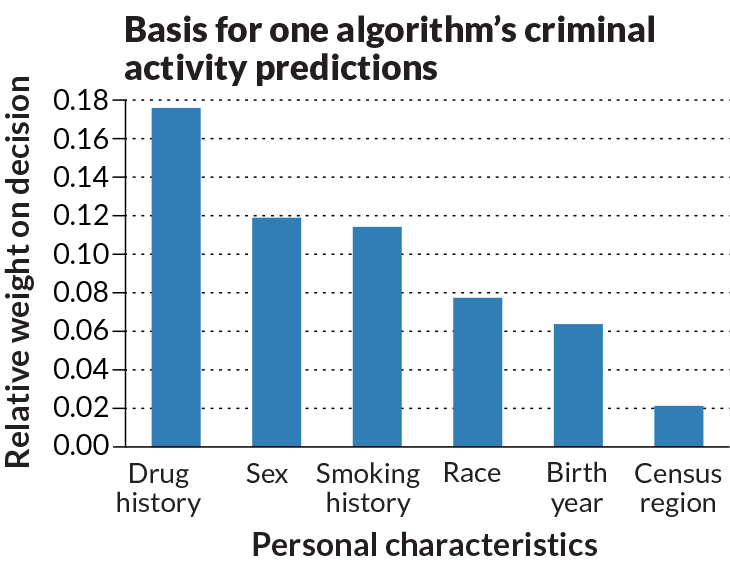
Source: A. Datta, S. Sen and Y. Zick/IEEE Symposium on Security and Privacy 2016
The effort to curb machine bias is still in its nascent stages. “I’m not aware of any system either identifying or resolving discrimination that’s actively deployed in any application,” says Nathan Srebro, a computer scientist at the University of Chicago. “Right now, it’s mostly trying to figure things out.”
Computer scientist Suresh Venkatasubramanian agrees. “Every research area has to go through this exploration phase,” he says, “where we may have only very preliminary and half-baked answers, but the questions are interesting.”
Still, Venkatasubramanian, of the University of Utah in Salt Lake City, is optimistic about the future of this important corner of computer and data science. “For a couple of years now … the cadence of the debate has gone something like this: ‘Algorithms are awesome, we should use them everywhere. Oh no, algorithms are not awesome, here are their problems,’ ” he says. But now, at least, people have started proposing solutions, and weighing the various benefits and limitations of those ideas. So, he says, “we’re not freaking out as much.”
This story appears in the September 16, 2017 issue of Science News with the headline, “Fair-minded machines: A new drive to revamp artificial intelligence may cut down bias.”