Is redoing scientific research the best way to find truth?
During replication attempts, too many studies fail to pass muster
REPEAT PERFORMANCE By some accounts, science is facing a crisis of confidence because the results of many studies aren’t confirmed when researchers attempt to replicate the experiments.
Harry Campbell
R. Allan Mufson remembers the alarming letters from physicians. They were testing a drug intended to help cancer patients by boosting levels of oxygen-carrying hemoglobin in their blood.
In animal studies and early clinical trials, the drug known as Epo (for erythropoietin) appeared to counteract anemia caused by radiation and chemotherapy. It had the potential to spare patients from the need for blood transfusions. Researchers also had evidence that Epo might increase radiation’s tumor-killing power.
But when doctors started giving Epo or related drugs, called erythropoietic-stimulating agents, to large numbers of cancer patients in clinical trials, it looked like deaths increased. Physicians were concerned, and some stopped their studies early.
At the same time, laboratory researchers were collecting evidence that Epo might be feeding rather than fighting tumors. When other scientists, particularly researchers who worked for the company that made the drug, tried to replicate the original findings, they couldn’t.
Scientists should be able to say whether Epo is good or bad for cancer patients, but seven years later, they still can’t. The Epo debate highlights deeper trouble in the life sciences and social sciences, two fields where it appears particularly hard to replicate research findings. Replicability is a cornerstone of science, but too many studies are failing the test.
“There’s a community sense that this is a growing problem,” says Lawrence Tabak, deputy director of the National Institutes of Health. Early last year, NIH joined the chorus of researchers drawing attention to the problem, and the agency issued a plan and a call to action.
Unprecedented funding challenges have put scientists under extreme pressure to publish quickly and often. Those pressures may lead researchers to publish results before proper vetting or to keep hush about experiments that didn’t pan out. At the same time, journals have pared down the section in a published paper devoted to describing a study’s methods: “In some journals it’s really a methods tweet,” Tabak says. Scientists are less certain than ever that what they read in journals is true.
Many people say one solution to the problem is to have independent labs replicate key studies to validate their findings. The hope is to identify where and why things go wrong. Armed with that knowledge, the replicators think they can improve the reliability of published reports.
Others call that quest futile, saying it’s difficult — if not impossible — to redo a study exactly, especially when working with highly variable subjects, such as people, animals or cells. Repeating published work wastes time and money, the critics say, and it does nothing to advance knowledge. They’d prefer to see questions approached with a variety of different methods. It’s the general patterns and basic principles — the reproducibility of a finding, not the precise replication of a specific experiment — that really matter.
It seems that everyone has an opinion about the underlying causes leading to irreproducibility, and many have offered solutions. But no one really knows entirely what is wrong or if any of the proffered fixes will work.
Much of the controversy has centered on the types of statistical analyses used in most scientific studies, and hardly anyone disputes that the math is a major tripping point. An influential 2005 paper looking at the statistical weakness of scientific studies generated much of the self-reflection taking place within the medical community over the last decade. While those issues still exist, especially as more complex analyses are applied to big data studies, there remain deeper problems that may be harder to fix.
Taking sides
Epo researchers weren’t the first to find discrepancies in their results, but their experience set the stage for much of the current controversy.
Story continues below infographic
Wrong answers
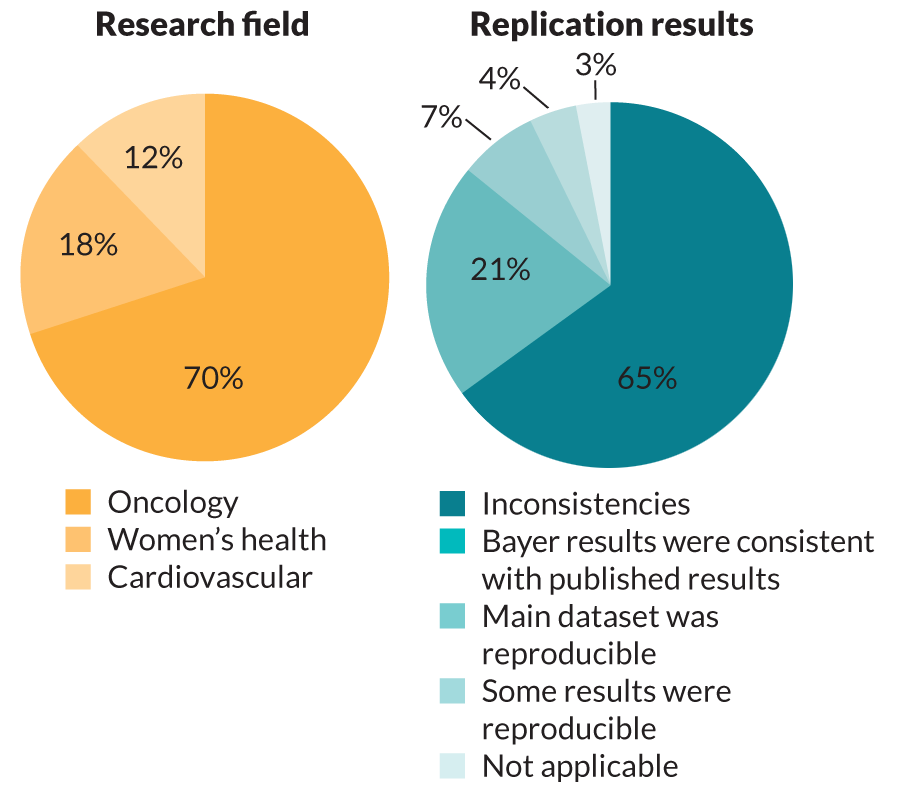
The Bayer pharmaceutical company tried to repeat studies in three research fields (gold chart), mostly cancer studies. Almost two-thirds of the redos (dark teal) produced results inconsistent with the original findings.
Source: F. Prinz et al/Nature Reviews Drug Discovery 2011
Mufson, head of the National Cancer Institute’s Cancer Immunology and Hematology Etiology Branch, organized a two-day workshop in 2007 where academic, government and pharmaceutical company scientists, clinicians and patient advocates discussed the Epo findings.
A divide quickly emerged between pharmaceutical researchers and scientists from academic labs, says Charles Bennett, an oncologist at the University of South Carolina.
Bennett was part of a team that had reported in 2005 that erythropoietin reduced the need for blood transfusions and possibly improved survival among cancer patients. But he came to the meeting armed with very different data. He and colleagues found that erythropoietin and darbepoetin used to treat anemia in cancer patients raised the risk of blood clots by 57 percent and the risk of dying by about 10 percent. Others found that people with breast or head and neck cancers died sooner than other cancer patients if they took Epo.
Those who argued that Epo was harmful to patients cited cellular mechanisms: tumor cells make more Epo receptors than other cells. More receptors, the researchers feared, meant the drug was stimulating growth of the cancer cells, a finding that might explain why patients were dying.
Company scientists from Amgen, which makes Epo drugs, charged that they had tried and could not replicate the results published by the academic researchers. After listening to the researchers hash through data for two days, Bennett could see why there was conflict. The company and academic scientists couldn’t even agree on what constituted growth of tumor cells, or on the correct tools for detecting Epo receptors on tumor cells, he says. That disconnect meant neither side would be able to confirm the other’s findings, nor could they completely discount the results. The meeting ended with a list of concerns and direction for future studies, but little consensus.
“I went in thinking it was black and white,” Bennett says. “Now, I’m very much convinced it’s a gray answer and everybody’s right.”
From there, pressure continued to build. In 2012, Amgen caused shock waves by reporting that it could independently confirm only six of 53 “landmark” papers on preclinical cancer studies. Replicating results is one of the first steps companies take before investing in further development of a drug. Amgen will not disclose how it conducted the replication experiments or even which studies it tried to replicate. Bennett suspects the controversial Epo experiments were among the chosen studies, perhaps tinting the results.
Amgen’s revelation came on the heels of a similar report from the pharmaceutical company Bayer. In 2011, three Bayer researchers reported in Nature Reviews Drug Discovery that company scientists could fully replicate only about 20 to 25 percent of published preclinical cancer, cardiovascular and women’s health studies. Like Amgen, Bayer did not say which studies it attempted to replicate. But those inconsistencies could mean the company would have to drop projects or expend more resources to validate the original reports.
Scientists were already uneasy because of a well-known 2005 essay by epidemiologist John Ioannidis, now at Stanford University. He had used statistical arguments to contend that most research findings are false. Faulty statistics often indicate a finding is true when it is not. Those falsely positive results usually don’t replicate.
Academic scientists have had no easier time than drug companies in replicating others’ results. Researchers at MD Anderson Cancer Center in Houston surveyed their colleagues about whether they had ever had difficulty replicating findings from published papers. More than half, 54.6 percent, of the 434 respondents said that they had, the survey team reported in PLOS ONE in 2013. Only a third of those people were able to correct the discrepancy or explain why they got different answers.
“Those kinds of studies are sort of shocking and worrying,” says Elizabeth Iorns, a biologist at the University of Miami in Florida and chief executive officer for Science Exchange, a network of labs that attempt to independently validate research results.
Over the long term, science is a self-correcting process and will sort itself out, Tabak and NIH director Francis Collins wrote last January in Nature. “In the shorter term, however, the checks and balances that once ensured scientific fidelity have been hobbled. This has compromised the ability of today’s researchers to reproduce others’ findings,” Tabak and Collins wrote. Myriad reasons for the failure to reproduce have been given, many involving the culture of science. Fixing the problem is going to require a more sophisticated understanding of what’s actually wrong, Ioannidis and others argue.
Two schools of thought
Researchers don’t even agree on whether it is necessary to duplicate studies exactly, or to validate the underlying principles, says Giovanni Parmigiani, a statistician at the Dana-Farber Cancer Institute in Boston. Scientists have two schools of thought about verifying someone else’s results: replication and reproducibility. The replication school teaches that researchers should retrace all of the steps in a study from data generation through the final analysis to see if the same answer emerges. If a study is true and right, it should.
Proponents of the other school, reproducibility, contend that complete duplication only demonstrates whether a phenomenon occurs under the exact conditions of the experiment. Obtaining consistent results across studies using different methods or groups of people or animals is a more reliable gauge of biological meaningfulness, the reproducibility school teaches. To add to the confusion, some scientists reverse the labels.
Timothy Wilson, a social psychologist at the University of Virginia in Charlottesville, is in the reproducibility camp. He would prefer that studies extend the original findings, perhaps modifying variables to learn more about the underlying principles. “Let’s try to discover something,” he says. “This is the way science marches forward. It’s slow and messy, but it works.”
But Iorns and Brian Nosek, a psychologist and one of Wilson’s colleagues at the University of Virginia, are among those who think exact duplication can move research in the right direction.
In 2013, Nosek and his former student Jeffrey Spies cofounded the Center for Open Science, with the lofty goal “to increase openness, integrity and reproducibility of scientific research.” Their approach was twofold: provide infrastructure to allow scientists to more easily and openly share data and conduct research projects to repeat studies in various disciplines in science.
Soon, Nosek and Iorns’ Science Exchange teamed up to replicate 50 of the most important (defined as highly cited) cancer studies published between 2010 and 2012. On December 10, 2014, the Reproducibility Project: Cancer Biology kicked off when three groups announced in the journal eLife their intention to replicate key experiments from previous studies and shared their plans for how to do it.
Iorns, Nosek and their collaborators hope the effort will give scientists a better idea of the reliability of these studies. If the replication efforts fail, the researchers want to know why. It’s possible that the underlying biology is sound, but that some technical glitch prevents successful replication of the results. Or the researchers may have been barking up the wrong tree. Most likely the real answer is somewhere in the middle.
Neuroscience researchers realized the value of duplicating studies with therapeutic potential early on. In 2003, the National Institute of Neuro-logical Disorders and Stroke contracted labs to redo some important spinal cord injury studies that showed promise for helping patients. Neuroscientist Oswald Steward of the University of California, Irvine School of Medicine heads one of the contract labs.
Story continues below table
Survey says …
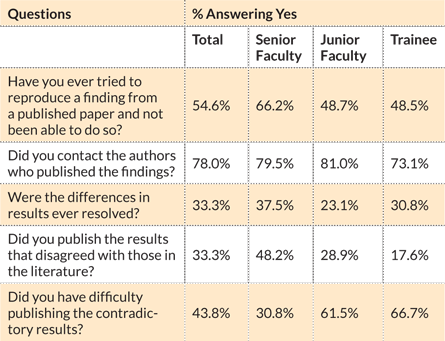
Academic researchers have trouble duplicating other researchers’ published results, a survey from MD Anderson Cancer Center suggests. Researchers, especially junior faculty members and trainees, often don’t resolve discrepancies and tend not to publish conflicting reports.
Source: A. Mobley et al/PLOS ONE 2013
Of the 12 studies Steward and colleagues tried to copy, they could fully replicate only one. And only after the researchers determined that the ability of a drug to limit hemorrhaging and nerve degeneration near an injury depended upon the exact mechanism that produced the injury. Half the studies could not be replicated at all and the rest were partially replicated, or produced mixed or less robust results than the originals, according to a 2012 report in Experimental Neurology.
Notably, the researchers cited 11 reasons that might account for why previous studies failed to replicate; only one was that the original study was wrong. Exact duplications of original studies are impossible, Steward and his colleagues contend.
Acts of aggression
Before looking at cancer studies, Nosek investigated his own field with a large collaborative research project. In a special issue of Social Psychology published last April, he and other researchers reported results of 15 replication studies testing 26 psychological phenomena. Of 26 original observations tested, they could only replicate 10. That doesn’t mean the rest failed entirely; several of the replication studies got similar or mixed results to the original, but they couldn’t qualify as a success because they didn’t pass statistical tests.
Simone Schnall conducted one of the studies that other researchers claimed they could not replicate. Schnall, a social psychologist at the University of Cambridge, studies how emotions affect judgment.
She has found that making people sit at a sticky, filthy desk or showing them revolting movie scenes not only disgusts them, it makes their moral judgment harsher. In 2008, Schnall and colleagues examined disgust’s flip side, cleanliness, and found that hand washing made people’s moral judgments less harsh.
M. Brent Donnellan, one of the researchers who attempted to replicate Schnall’s 2008 findings, blogged before the replication study was published that his group made two unsuccessful attempts to duplicate Schnall’s original findings. “We gave it our best shot and pretty much encountered an epic fail as my 10-year-old would say,” he wrote. When Schnall and others complained that the comments were unprofessional and pointed out several possible reasons the study failed to replicate, Donnellan, a psychologist at Texas A&M University in College Station, apologized for the remark, calling it “ill-advised.”
Schnall’s criticism set off a flurry of negative remarks from some researchers, while others leapt to her defense. The most vociferous of her champions have called replicators “bullies,” “second-stringers” and worse. The experience, Schnall said, has damaged her reputation and affected her ability to get funding; when decision makers hear about the failed replication they suspect she did something wrong.
“Somehow failure to replicate is viewed as more informative than the original studies,” says Wilson. In Schnall’s case, “For all we know it was an epic fail on the replicators’ part.”
The scientific community needs to realize that it is difficult to replicate a study, says Ioannidis. “People should not be shamed,” he says. Every geneticist, himself included, has published studies purporting to find genetic causes of disease that turned out to be wrong, he says.
Iorns is not out to stigmatize anyone, she says. “We don’t want people to feel like we’re policing them or coming after them.” She aims to improve the quality of science and scientists. Researchers should be rewarded for producing consistently reproducible results, she says. “Ultimately it should be the major criteria by which scientists are assessed. What could be more important?”
Variable soup
Much of the discussion of replicability has centered on social and cultural factors that contribute to publication of irreplicable results, but no one has really been discussing the mechanisms that may lead replication efforts to fail, says Benjamin Djulbegovic, a clinical researcher at the University of South Florida in Tampa. He and long-time collaborator mathematician Iztok Hozo of Indiana University Northwest in Gary have been mulling over the question for years, Djulbegovic says.
They were inspired by the “butterfly effect,” an illustration of chaos theory that one small action can have major repercussions later. The classic example holds that a butterfly flapping its wings in Brazil can brew a tornado in Texas. Djulbegovic hit on the idea that there’s chaos at work in most biology and psychology studies as well.
Changing even a few of the original conditions of an experiment can have a butterfly effect on the outcome of replication attempts, he and Hozo reported in June in Acta Informatica Medica. The two researchers considered a simplified case in which 12 factors may affect a doctor’s decision on how to treat a patient. The researchers focused on clinical decision making, but the concept is applicable to other areas of science, Djulbegovic says. Most of the factors, such as the decision maker’s time pressure (yes or no) or cultural factors (present or not important) have two possible starting places. The doctor’s individual characteristics — age (old or young), gender (male or female) — could have four combinations and the decision maker’s personality had five different modes. All together, those dozen initial factors make up 20,480 combinations that could represent the initial conditions of the experiment.
That didn’t even include variables about where exams took place, the conditions affecting study participants (Were they tired? Had they recently fought with a loved one or indulged in alcohol?), or the handling of biological samples that might affect the diagnostic test results. Researchers have good and bad days too. “You may interview people in the morning, but nobody controls how well you slept last night or how long it took you to drive to work,” Djulbegovic says. Those invisible variables may very well influence the medical decisions made that day and therefore affect the study’s outcome.
Djulbegovic and Hozo varied some of the initial conditions in computer simulations. If initial conditions varied between experiments by 2.5 conditions or less, the results were highly consistent, or replicable. But changing 3.5 to four initial factors gave answers all over the map, indicating that very slight changes in initial conditions can render experiments irreproducible.
The study is not rigorous mathematical proof, Djulbegovic says. “We just sort of put some thoughts in writing.”
Balancing act
Failed replications may offer scientists some valuable insights, Steward says. “We need to recognize that many results won’t make it through the translational grist mill.” In other words, a therapy that shows promise under specific conditions, but can’t be replicated in other labs, is not ready to be tried in humans.
“In many cases there’s a biological story there, but it’s a fragile one,” Steward says. “If it’s fragile, it’s not translatable.”
That doesn’t negate the original findings, he says. “It changes our perspective on what it takes to get a translatable result.”
Nosek, proponent of replication that he is, admits that scientists need room for error. Requiring absolute replicability could discourage researchers from ever taking a chance, producing only the tiniest of incremental advances, he says. Science needs both crazy ideas and careful research to succeed.
“It’s totally OK that you have this outrageous attempt that fails,” Nosek says. After all, “Einstein was wrong about a lot of stuff. Newton. Thomas Edison. They had plenty of failures, too.” But science can’t survive on bold audacity alone, either. “We need a balance of innovation and verification,” Nosek says.
How best to achieve that balance is anybody’s guess. In their January 2014 paper, Collins and Tabak reviewed NIH’s plan, which includes training modules for teaching early-career scientists the proper way to do research, standards for committees reviewing research proposals and an emphasis on data sharing. But the funding agency can’t change things alone.
In November, in response to the NIH call to action, more than 30 major journals announced that they had adopted a set of guidelines for reporting results of preclinical studies. Those guidelines include calls for more rigorous statistical analyses, detailed reporting on how the studies were done, and a strong recommendation that all datasets be made available upon request.
Ioannidis offered his own suggestions in the October PLOS Medicine. “We need better science on the way science is done,” he says. He helped start the Meta-Research Innovation Center at Stanford to conduct research on research and figure out how to improve it.
In the decade since he published his assertion of the wrongness of research, Ioannidis has seen change. “We’re doing better, but the challenges are even bigger than they were 10 years ago,” he says.
He is reluctant to put a number on science’s reliability as a whole, though. “If I said 55 to 65 percent [of results] are not replicable, it would not do justice to the fact that some types of scientific results are 99 percent likely to be true.”
Science is not irrevocably broken, he asserts. It just needs some improvements.
“Despite the fact that I’ve published papers with pretty depressive titles, I’m actually an optimist,” Ioannidis says. “I find no other investment of a society that is better placed than science.”
This article appeared in the January 24, 2015 issue of Science News with the headline “Repeat Performance.”







